28
What Are Robots.txt Files? A Comprehensive Guide
Learn everything you need to know about robots.txt files, their purpose, and how they impact your website's SEO. This guide explains the structure and usage of these files, along with best practices for implementation. Use our free tool to create and manage your robots.txt file: Robots.txt Builder Tool.
Introduction
Robots.txt files play a vital role in managing how search engines crawl and index your website. Understanding what these files are and how to use them effectively can significantly impact your site's visibility and SEO performance. In this article, we will explore the definition, purpose, structure, and best practices for implementing robots.txt files on your website.
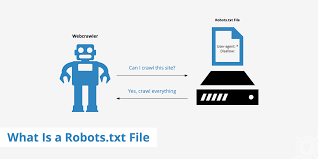
What is a Robots.txt File?
A robots.txt file is a text file placed in the root directory of a website to communicate with web crawlers and robots. It tells these automated systems which pages or sections of your site should be crawled and indexed by search engines and which should be excluded.
Purpose of Robots.txt Files
The primary purposes of robots.txt files include:
- Controlling Crawling
By specifying which pages should not be crawled, you can prevent search engines from wasting resources on low-value or duplicate content, which can enhance your site’s overall SEO. - Preventing Indexing of Certain Content
If you have sensitive or irrelevant pages (like admin areas or test pages), using a robots.txt file allows you to keep these pages from being indexed in search engine results. - Managing Server Load
If your site is large or has limited server resources, a robots.txt file can help manage the load by restricting crawling on less important pages.
Structure of a Robots.txt File
A robots.txt file follows a simple syntax, consisting of directives that specify user-agents (web crawlers) and rules for them. Here’s a basic structure:
vbnet Copy codeUser-agent: [name of the robot] Disallow: [URL string not to be crawled] User-agent: * Disallow: /private/ Disallow: /temp/
In this example:
- User-agent: Specifies the web crawler to which the rules apply. Using * means the rules apply to all crawlers.
- Disallow: Indicates the URLs that should not be crawled. A blank line after the Disallow directive means all pages are allowed.
Best Practices for Robots.txt Files
To effectively use robots.txt files, follow these best practices:
- Place the File in the Root Directory
Ensure your robots.txt file is located in the root directory of your website (e.g., www.example.com/robots.txt) so that search engines can easily find it. - Use Specific User-agent Directives
If you want to restrict certain crawlers while allowing others, specify the user-agent name rather than using the wildcard (*) for all robots. - Test Your Robots.txt File
Use online testing tools to verify that your robots.txt file is correctly configured and that it does not unintentionally block important pages. Our free tool can help you create and test your robots.txt file: Robots.txt Builder Tool. - Keep It Simple
Avoid overly complex rules. Simplicity ensures that your directives are easily understood by crawlers and reduces the risk of errors. - Regularly Update Your File
As your website evolves, so should your robots.txt file. Regularly review and update it to reflect any changes in your site structure or SEO strategy.
Conclusion
Robots.txt files are an essential component of SEO management that allows website owners to control how search engines crawl and index their content. By implementing these files correctly, you can optimize your site’s performance and ensure that valuable pages are prioritized in search engine results. To get started with your own robots.txt file, utilize our free tool: Robots.txt Builder Tool and take control of your website's indexing today!
Contact
Missing something?
Feel free to request missing tools or give some feedback using our contact form.
Contact Us